
中央处理器-凯发旗舰厅
中央处理器,英文名:central processing unit(简称:cpu)它是超大规模集成电路,是一台计算机的运算核心和控制核心。主要包括运算器(alu,算术 和逻辑 单位)和控制器(铜,控制 单元)两大部件。此外,它还包括几个寄存器和高速缓冲存储器以及实现它们之间关系的数据、控制和状态总线。它与内存和输入相关联/输出设备统称为电子计算机的三大核心部件。它的主要功能是解释计算机指令和处理计算机软件中的数据。电脑的性能很大程度上是由cpu的性能决定的,而cpu的性能主要体现在它运行程序的速度上。
简介定义
中央处理器(cpu),是电子计算机的主要设备之一,也是计算机中的核心配件。它的主要功能是解释计算机指令和处理计算机软件中的数据。cpu是计算机中的核心部件,负责读取解码和执行指令。中央处理器主要包括两部分,即控制器、算术单元,它还包括高速缓冲存储器和实现它们之间关系的数据、控制的总线。电子计算机的三个核心部件是中央处理器、内部存储器、输入/输出设备。中央处理器的功能主要是处理指令、执行操作、控制时间、处理数据。 https://www.qwbaike.cn
在计算机体系结构中,cpu 是计算机的所有硬件资源(如存储器、输入输出单元)进行控制调配、一种执行一般操作的核心硬件部件。cpu 是计算机的计算和控制核心。计算机系统中所有软件层的操作最终都会通过指令集映射到cpu的操作上。
famous encyclopedia string
物理结构

famous encyclopedia string
cpu 包括一个算术逻辑单元、寄存器单元和控制单元等
famous encyclopedia string
famous encyclopedia string
逻辑部件
英文逻辑组件;运算逻辑部件。您可以执行定点或浮点算术运算、还可以执行移位操作和逻辑操作地址操作和转换。
寄存器
包括寄存器的寄存器单元、特殊寄存器和控制寄存器。通用寄存器可分为定点数和浮点数,用于存储指令执行过程中临时存储的寄存器操作数(或最终)的操作结果。通用寄存器是中央处理器的重要组成部分之一。 famous encyclopedia string
控制部件
英文控制单元;控制单元主要负责解码指令,并为每个指令要执行的每个操作发出控制信号。 famous encyclopedia string
其结构有两种:一种是以微存储器为核心的微程序控制方式;一种是基于逻辑硬接线结构的控制模式。
qwbaike.cn
微存储器保存微码,每个微码对应一个最基本的微操作,也称为微指令;每条指令由不同的微码序列组成,这些微码序列构成一个微程序。指令解码后,中央处理器发出一定时序的控制信号,以一个微周期为节拍,按照给定的顺序执行这些微码确定的若干微操作,从而完成一条指令的执行。简单指令是由(3~5)一个微操作,复杂的指令是由几十个甚至上百个微操作组成的。
famous encyclopedia string
主要功能
处理指令
英文处理 指令;这是指控制程序中指令的执行顺序。程序中的指令之间有严格的顺序,必须严格按照程序中规定的顺序执行,以保证计算机系统的正确性。
执行操作
英文执行 和 操作;指令的功能通常由计算机中的组件执行的一系列操作来实现。根据指令的功能,cpu会产生相应的操作控制信号并发送给相应的部件,从而控制这些部件按照指令的要求动作。
famous encyclopedia string
控制时间
英文控件 时间;时间控制是各种操作的计时。在一条指令的执行过程中,应该严格控制在什么时间做什么。只有这样,计算机才能有条不紊地工作。 famous encyclopedia string
处理数据
即对数据进行算术和逻辑运算,或其他信息处理。 famous encyclopedia string
它的主要功能是解释计算机指令,处理计算机软件中的数据并执行指令。在微型计算机中,又称微处理器,计算机的所有操作都由cpu控制,cpu的性能指标直接决定了微型计算机系统的性能指标。cpu有以下四个基本功能:数据通信,资源共享,分布式处理,提供系统可靠性。操作原理基本可以分为四个阶段:提取(fetch)解码(decode)执行(execute)和写回(写回)
工作过程
cpu从内存或缓存中获取指令,将它们放入指令寄存器,并对指令进行解码。它将一条指令分解成一系列微操作,然后发出各种控制命令执行微操作系列,从而完成一条指令的执行。指令是计算机指定运算类型和操作数的基本命令。指令由一个或多个字节组成,包括操作码字段、与操作数地址有关的一个或多个字段,以及一些表示机器状态的状态字和特征代码。有些指令还直接包含操作数本身。
提取
第一阶段是从内存或高速缓存中获取和检索指令(是一个数值或一系列数值)由(程序 计数器)指定内存的位置。程序计数器保存用于识别程序位置的数值。换句话说,程序计数器记录了cpu在程序中的踪迹。
解码
famous encyclopedia string
解码线路 famous encyclopedia string
cpu根据从存储器中提取的指令确定其执行行为。在解码阶段,指令被分解成有意义的片段。根据cpu的指令集体系结构(isa)定义如何将值解释为指令。部分指令值是操作码(opcode),指示要执行的操作。其他值通常为指令提供必要的信息,如加法(添加)运算的运算目标。 qwbaike.cn
执行
在提取和解码阶段之后,它立即进入执行阶段。在这个阶段,它被连接到能够执行所需操作的各种cpu组件。 famous encyclopedia string
例如,需要加法运算和算术逻辑单元(算术逻辑单元)将连接到一组输入和一组输出。输入提供要相加的值,输出将包含求和的结果。alu包含电路系统,使得输出端很容易完成简单的普通运算和逻辑运算(例如加法和位运算)如果加法运算产生的结果太大,cpu无法处理,则可能会在标志寄存器中设置运算溢出(算术 溢出)标志。 qwbaike.cn
写回
在最后一个阶段,写回,执行阶段的结果只是以某种格式写回。运算结果通常被写入cpu的内部寄存器,以便后续指令快速访问。在其他情况下,可以将运算结果写入速度较慢但容量较大成本较低的主存储器。一些类型的指令操作程序计数器而不直接产生结果。这些一般称作“跳转”jumps)并在程序中引入循环行为、条件性执行(透过条件跳转)和函式。许多指令会改变标志寄存器的状态位。这些标志可以用来影响程序行为,因为它们经常显示各种操作结果。例如,以一个“比较”该指令判断两个值的大小,并根据比较结果在标志寄存器上设置一个值。该标志可用于通过后续跳转指令确定程序趋势。执行完指令写回结果后,程序计数器值会增加,重复整个过程,在下一个指令周期正常取下一条顺序指令。 famous encyclopedia string
性能参数
电脑的性能很大程度上是由cpu的性能决定的,而cpu的性能主要体现在它运行程序的速度上。影响运行速度的性能指标包括cpu的工作频率、cache容量、指令系统和逻辑结构等参数。 www.qwbaike.cn
主频
主频也叫时钟频率,单位是兆赫(mhz)或千兆赫(ghz)一个,表示cpu的操作、处理数据的速度。一般来说,主频越高,cpu处理数据的速度越快。 famous encyclopedia string
cpu主频=外部频率×倍频系数。主频和实际运行速度有一定的关系,但不是简单的线性关系。所以cpu的主频和cpu的实际运算能力没有直接关系,主频表示的是cpu中数字脉冲信号振荡的速度。你也可以在英特尔 的处理器产品:1ghzitanium芯片的行为几乎可以像2.66ghz至强(xeon)opteron一样快,还是1.5ghzitanium2大约跟4gz至强/opteron也一样快。cpu的运行速度取决于cpu的流水线、总线和其他性能指标。 famous encyclopedia string
外频
外部频率是cpu的参考频率,单位是mhz。cpu的外接频率决定了整个主板的运行速度。一般来说,在台式机中,超频就是超级cpu的外频(当然,一般情况下,cpu的倍频是锁定的)我相信这个很好理解。但是对于服务器cpu来说,超频是绝对不允许的。前面说过,cpu决定主板的运行速度,两者是同步运行的如果服务器cpu超频,改变外部频率,就会出现异步运行(桌面很多主板都支持异步操作)这会造成整个服务器系统的不稳定。 famous encyclopedia string
在大多数计算机系统中,外部频率并不与主板的前端总线同步,而是与前端总线同步(fsb)频率又容易混淆。
www.qwbaike.cn
总线频率

amd 骁龙ii x4 955黑匣子 https://www.qwbaike.cn
前端总线(fsb)是连接cpu和北桥芯片的总线。前端总线(fsb)频率(即总线频率)它直接影响cpu和内存直接数据交换的速度。有一个公式可以计算,就是数据带宽=(总线频率×数据位宽度)8数据传输的最大带宽取决于同时传输的所有数据的宽度和传输频率。比如支持64位的xeon nocona,前端总线800mhz根据公式,其最大数据传输带宽为6.4gb/秒。 https://www.qwbaike.cn
外频与前端总线(fsb)频率的区别:前端总线的速度是指数据传输的速度,外部频率是指cpu和主板同步运行的速度。也就是说,100mhz的外部频率是指每秒振荡1亿次的数字脉冲信号;100mhz前端总线是指cpu每秒可接受的数据传输能力为100mhz×64bit÷8bit/字节=800mb/s。 https://www.qwbaike.cn
倍频系数
倍频系数是指cpu主频与外部频率的相对比例关系。在外部频率相同的情况下,倍频越高,cpu频率越高。但其实在外频不变的前提下,高频cpu本身意义不大。这是因为cpu和系统之间的数据传输速度是有限的,盲目追求高频率,得到高倍频的cpu会明显出现“瓶颈”效应-cpu从系统获取数据的极限速度无法满足cpu的运算速度。一般来说,除了英特尔 s cpu,倍频被锁定少数cpu如奔腾双核e6500k带intel core 2 core和一些extreme版本不锁频,而amd没有 之前不要上锁amd推出了cpu的黑盒版本(即用户可以在不锁定倍频版本的情况下自由调节倍频,调节倍频的超频模式比调节外频要稳定得多)
缓存
缓存大小也是cpu的重要指标之一,缓存的结构和大小对cpu的速度影响很大cpu中的缓存运行频率非常高,通常与处理器同频,工作效率远大于系统内存 和硬盘。在实际工作中,cpu经常需要重复读取同一个数据块,缓存容量的增加可以大大提高cpu内部读取数据的命中率,而无需在内存或硬盘中寻找,从而提高系统性能。但是由于cpu芯片面积和成本的因素,缓存很小。 famous encyclopedia string
l1cache(一级缓存)它是cpu的第一层缓存,分为数据缓存和指令缓存。内置l1缓存的容量和结构对cpu的性能有很大影响然而,高速缓冲存储器都是由静态ram构成的,并且结构复杂在cpu芯片面积不能太大的情况下,l1级缓存的容量不能做得太大。通常,服务器cpu的l1缓存容量通常为32-256kb。
famous encyclopedia string
l2cache(二级缓存)它是cpu的第二层缓存,分为内部和外部芯片。内部芯片二级缓存运行速度与主频相同,而外部二级缓存只有主频的一半。l2缓存容量也会影响cpu的性能原则是cpu越大越好以前国内最大的cpu容量是512kb,在笔记本电脑上也能达到2m,而服务器和工作站使用的cpu l2缓存更高,达到8m以上。
l3cache(三级缓存),分为两种,早期是外置,内存延迟,同时提高处理器在计算大量数据时的性能。降低内存延迟,提高大数据的计算能力,对游戏很有帮助。但是,通过在服务器领域添加l3缓存,性能仍有显著提高。例如,具有较大l3缓存的配置将更有效地使用物理内存,因此它比较慢的磁盘i更有效/o子系统可以处理更多的数据请求。具有更大l3缓存的处理器提供了更高效的文件系统缓存行为以及更短的消息和处理器队列长度。
其实最早的l3缓存应用在amd发布的k6上-在iii处理器上,当时的l3缓存受制造工艺限制,没有集成到芯片中,而是集成在主板上。l3缓存,只能和系统总线频率同步,和主存区别不大。后来,英特尔 面向服务器市场的安腾处理器。然后是p4ee和至强mp。英特尔还计划在未来推出9mbl3缓存的itanium2处理器和24mbl3缓存的双核itanium2处理器。
但是l3缓存对于提高处理器的性能并不是很重要比如配备1mbl3缓存的xeonmp处理器仍然不是骁龙的对手,这说明前端总线的增加会比缓存的增加带来更有效的性能提升。
qwbaike.cn
制造工艺
cpu制造工艺的微米是指ic中电路之间的距离。制造技术的趋势是向更高密度发展。ic电路设计的密度越高,就意味着在同样尺寸和面积的ic中,你可以拥有更高的密度、功能更复杂的电路设计。主180nm、130nm、90nm、65nm、45纳米、22纳米,英特尔已经在2010年发布了采用32纳米制造工艺的酷睿i3/酷睿i5/酷睿i7系列,并于2012年4月发布了22纳米酷睿i3/i5/i7系列。此外,我们还计划推出14纳米产品(据新闻报道,14纳米将于2013年下半年在笔记本电脑处理器中推出。而amd则表示、自己的产品会直接跳过32nm工艺(2010年第三季度生产了一些32纳米产品、如orochi、llano)在2011年中期和早期发布28纳米产品(apu)trinityapu于2012年10月2日正式发布,工艺还是32nm,28nm工艺代号kaveri一再推迟。2013年推出的28纳米apu只有用于平板电脑和笔记本的低端处理器,代号为kabini。而且鲜为人知,市场反应正常。据可靠消息称,2014年上半年可能会发布一款28nm桌面apu,其gpu将采用gcn架构,与高端a卡相同。
www.qwbaike.cn
指令集
cpu依赖于来自计算和的指令,每个cpu都设计有一系列与其硬件电路相匹配的指令系统。指令的强弱也是cpu的重要指标,指令集是提高微处理器效率最有效的工具之一。 qwbaike.cn
从目前的主流架构来看,指令集可以分为两部分复杂指令集和简化指令集(有四种类型的指令集)以及来自特定应用,例如英特尔mmx(multi media extended,是amd 的猜测,英特尔没有解释词源)sse、sse2(流动-单个 指令多个 数据-分机 2)sse3、sse4系列和amd s 3dnow!等等都是cpu的扩展指令集,分别增强了cpu的多媒体、图形图像互联网等处理能力。
cpu的扩展指令集通常被称为”cpu的指令集”sse3指令集也是最小的指令集以前,mmx包含57个命令,sse包含50个命令,sse2包含144个命令,sse3包含13个命令。
famous encyclopedia string
从586cpu开始,cpu的工作电压分为核心电压和i/o电压,通常cpu的核心电压小于等于i/o电压。其中,内核电压的大小取决于cpu的生产工艺一般生产工艺越小,内核的工作电压越低;i/o电压一般在1.6~5v。低电压可以解决功耗过大和发热量过大的问题。
www.qwbaike.cn
cisc
cisc指令集,也称为复杂指令集,在英语中被称为cisc(复杂 指令集 计算的缩写)在cisc微处理器中,程序的指令是顺序串行执行的,每个指令中的操作也是顺序串行执行的。顺序执行的优点是控制简单,但计算机各部分利用率不高,执行速度慢。其实就是intel生产的x86系列(也就是ia-32架构)cpu及其兼容cpu,如amd、via的。即使是新的x86-64(也称为amd64)都属于cisc的范畴。
https://www.qwbaike.cn
要知道什么是指令集,我们应该从今天开始s x86架构cpu。x86指令集是intel 的第一个16位cpu(i8086)特别开发,世界上的 ibm1981年推出的第一台个人电脑-i8088(i8086简化版)还使用了x86指令,在计算机中加入了x87芯片,提高了浮点数据处理能力从现在开始,x86指令集和x87指令集将统称为x86指令集。 famous encyclopedia string
虽然随着cpu技术的不断发展,intel已经陆续开发出了新型的i80386.i80486直到过去的pii至强、piii至强、奔腾 3,奔腾 4系列,最后是today s core 2系列、至强(不包括xeon nocona)但是,为了保证计算机能够继续运行过去开发的各种应用程序,以保护和继承丰富的软件资源,英特尔公司生产的所有cpu仍然使用x86指令集,因此其cpu仍然属于x86系列。因为intel x86系列及其兼容的cpu(如amd thlon mp、他们都使用x86指令集,所以今天 形成了庞大的x86系列和兼容的cpu阵容。x86cpu主要包括intel 的服务器cpu和amd 的服务器cpu。 www.qwbaike.cn
risc

famous encyclopedia string
中央处理器 famous encyclopedia string
risc是英文“简化 指令 集合 计算 ” 的缩写quot中文和英文quot意味着“精简指令集”他是由约翰 科克(约翰·科克)指出约翰 科克 他在ibm的第一个项目是研究拉伸计算机(世界上第一个“超级计算机”型号)他很快成为了大型机专家。1974年,cocke和他的研究小组开始尝试开发一种每秒能处理300个电话的电话交换网络。为了实现这个目标,他必须找到一种方法来提高现有交换系统架构的交换速率。1975年约翰 科克研究了ibm370 cisc(复杂 指令 集 计算,复杂指令集计算)系统,对cisc的测试表明,各种指令出现的频率差别很大,最常用的是一些简单的指令,它们只占指令总数的20%,但是程序中的频率是80%
famous encyclopedia string
复杂的指令系统必然增加微处理器的复杂度,导致开发时间长,成本高。而且复杂的指令需要复杂的运算,必然会拖慢计算机的速度。基于以上原因,risc cpu于80年代诞生与cisc cpu相比,risc cpu不仅简化了指令系统,而且采用了一种称为“超标量和超级流水线结构”,大大增加了并行处理能力。risc指令集是高性能cpu的发展方向。它不同于传统的cisc(复杂指令集)相对。相比之下,risc比复杂指令集有统一的指令格式更少的类型和更少的寻址方式。当然处理速度要高很多。这种指令系统的cpu广泛应用于中高端服务器,尤其是高端服务器,都采用risc指令系统cpu。risc指令系统更适合高端服务器操作系统windows 7,linux类似于windows os(unix)的操作系统。risc cpu在软件和硬件上与intel和amd cpu不兼容。
在高端服务器中,使用risc指令的cpu主要包括以下几类:powerpc处理器、sparc处理器、pa-risc处理器、mips处理器、阿尔法处理器。
www.qwbaike.cn
ia-64
epic(显式并行计算机,精确并行指令计算机)关于它是否是risc和cisc系统的继承者,一直有很多争论单说epic系统,更像是英特尔处理器走向risc系统的重要一步。理论上,在相同的主机配置下,epic系统设计的cpu比基于unix的应用软件要好得多。 qwbaike.cn
英特尔 采用epic技术的服务器cpu是安腾的安腾(开发代码是merced)它是86位处理器和ia-64系列的第一款。微软还开发了一个代号为win64的操作系统,由软件支持。英特尔采用x86指令集后,转向更先进的86-bit微处理器,intel这么做是因为他们想摆脱庞大的x86架构,引入精力充沛功能强大的指令集,所以采用了带有epic指令集的ia-64(x92)架构便诞生了。ia-(64 )x92)在很多方面,它比x86有了很大的进步。它突破了传统ia32架构在数据处理能力系统稳定性等方面的诸多限制、安全性、可用性、相当的合理性等方面实现了突破性的提升。 www.qwbaike.cn
ia-64微处理器最大的缺点是不兼容x86,而英特尔正在努力解决ia的问题-64处理器可以更好的运行两个朝代的软件,而且是在ia-64处理器上(itanium、钛2 …引入了x86-to-ia-64解码器,使x86指令可以翻译成ia-64指令。这个解码器不是最高效的解码器,也不是运行x86代码的最佳方式(最好的办法是直接在x86处理器上运行x86代码)所以运行x86应用时,itanium 和itanium2的性能很差。这也成为x86-64的根本原因。
处理技术
在解释超级流水线和超标量之前,先了解一下流水线(管道)流水线是英特尔第一次开始在486芯片中使用。装配线就像工业生产中的装配线一样工作。在cpu中由5-六个不同功能的电路单元组成一条指令处理流水线,然后将一条x86指令分成5条-六个步骤之后,这些电路单元会分别执行,这样一个cpu时钟周期就可以完成一条指令,从而提高cpu的运行速度。经典奔腾的每个整数流水线分为四个阶段,即指令预取、译码、执行、写回结果,浮点流水线分八个阶段。 famous encyclopedia string

超标量是通过建立多条流水线来同时执行多个处理器,其本质是以空间换时间。而超级管道就是通过细化流量、提高主频使一个内完成一个甚至多个操作成为可能,其本质是以时间换取空间。比如奔腾4的流水线就长达20级。管道设计的步骤(级)它越长,完成一条指令的速度就越快,因此可以适应工作频率更高的cpu。但是长流水线也带来了一些副作用,很可能高频率的cpu实际运行速度会更低,就像intel s奔腾4,虽然它的主频可以高达1.超过4g,但计算性能远不及amd1.2g athlon甚至奔腾iii。
famous encyclopedia string
famous encyclopedia string
cpu封装是将cpu芯片或cpu模块用特定的材料固化在里面,防止损坏的一种保护措施一般cpu只有包装好才能交付给用户。cpu的封装方式取决于cpu的安装形式和器件的一体化设计从大的分类来说,通常socket插座安装的cpu使用的是pga(栅格阵列)mode封装,slotx插槽安装的cpu都采用sec(单边接插盒)的形式封装。还有plga(塑料格栅阵列)olga(organiclandgridarray)等封装技术。由于市场竞争日益激烈,cpu封装技术的发展方向主要是节约成本。
https://www.qwbaike.cn
多线程
同时多线程同时多线程,简称超小型电子管。smt通过复制处理器上的结构状态,使同一处理器上的多个线程同步执行,共享处理器的执行资源,可以最大化的实现宽发射、乱序超标量处理可以提高处理器运算部件的利用率,缓解因数据相关性或缓存缺失而导致的访存延迟。当没有多线程可用时,smt处理器几乎与传统的宽发射超标量处理器相同。smt最吸引人的地方在于,只需小范围改变处理器内核的设计,几乎不增加额外成本,就能显著提升性能。多线程技术可以为高速计算核心准备更多的待处理数据,减少计算核心的空闲时间。这对于桌面低端系统来说无疑是很有吸引力的。intel从3.从06 ghz的奔腾4开始,一些处理器将支持smt技术。 www.qwbaike.cn
多核心
多核,也指芯片多处理器(芯片多处理器,简称金属波纹管金属波纹管)cmp是由美国斯坦福大学提出的它的想法是在大规模并行处理器中结合smp(对称多处理器)集成到同一个芯片中,每个处理器并行执行不同的进程。多个cpu同时并行运行程序是实现超高速计算的一个重要方向,称为并行处理。与cmp相比,smt处理器结构的灵活性更加突出。然而,当半导体工艺进入0.18微米以后,线延迟已经超过门延迟,这就要求微处理器的设计要更小,把它分成很多部分、局部性较好的基本单元结构。相比之下,cmp结构被划分为多个处理器核,每个核相对简单,有利于优化设计,因此更有发展前景。ibm 的power4芯片和sun s majc5200芯片采用cmp结构。多核处理器可以共享处理器内部的缓存,提高了缓存利用率,简化了多处理器系统设计的复杂度。但是,这并不意味着内核越多,性能越高比如16核cpu没有8核cpu快,因为核太多,无法合理分配,所以运行速度变慢。买电脑请酌情选择。2005年下半年,英特尔和amd的新处理器也将集成到cmp结构中。全新安腾处理器的开发代号为montecito,采用双核设计,拥有至少18mb片上缓存,采用90nm工艺制造。它的每个内核都有独立的l1l2和l3cache,包含大约10亿个晶体管。
https://www.qwbaike.cn
smp
smp(对称多重-处理)对称多处理架构symmetric multi processing architecture的缩写,意思是在一台计算机上组装一组处理器(多cpu)cpu共享内存子系统和总线结构。在这项技术的支持下,服务器系统可以同时运行多个处理器,并共享内存和其他主机资源。像双至强,也就是所谓的双路,这是对称处理器系统中最常见的一种(至强mp可以支持四个通道,amdopteron可以支持一个通道-8路)还有几辆16路公共汽车。不过一般来说,smp结构的机器扩展性很差,很难做到100个以上的处理器,一般是8到16个,但这对于大部分用户来说已经足够了。它在高性能服务器和工作站级主板架构中最为常见,例如可以支持多达256个cpu的系统的unix服务器。
构建smp系统的必要条件如下:支持smp的硬件包括主板和cpu;支持smp的系统平台,然后是支持smp的应用软件。为了使smp系统高效运行,操作系统必须支持smp系统,如winnt、linux、以及unix和其他32位操作系统。也就是说,可以执行多任务和多线程。多任务意味着操作系统可以让不同的cpu同时完成不同的任务;多线程是指操作系统让不同的cpu并行完成同一任务。 famous encyclopedia string
搭建一个smp系统,对选择的cpu有很高的要求首先,、apic必须内置在cpu中(高级编程中断控制器)单元。英特尔多处理规范的核心是高级可编程中断控制器(高级编程中断控制器–apics)的使用;再次,相同的产品型号,相同类型的cpu核心,完全相同的运行频率;最后,尽量保持相同的产品序列号,因为当两个生产批次的cpu作为双处理器运行时,可能会出现一个cpu过载,另一个cpu负担轻的情况,无法发挥最大性能,更严重的可能会导致死机。
numa技术
numa是一种非均匀访问分布式共享存储技术,它是由若干个独立的节点通过高速专用网络连接而成的系统,每个节点可以是单个cpu或smp系统。在numa,有许多解决缓存一致性的方法通常使用硬件技术来维护缓存的一致性,这通常需要操作系统来解决numa访问和内存的不一致性(本地存储器和远程存储器之间访问延迟和带宽的差异)进行专门的优化来提高效率,或者采用专门的软件编程方法来提高效率。numa系统的例子。有三个smp模块通过一个高速专用网络连接起来组成一个节点,每个节点可以有12个cpu。像sequent这样的系统最多可以有64个甚至256个cpu。显然,这是smp和numa技术的结合。
famous encyclopedia string
乱序执行
乱序执行(out-of-订单执行),指的是cpu允许多条指令不按程序规定的顺序开发,并发送到相应的电路单元进行处理的技术。这样可以提前执行的指令会根据每个电路单元的状态和每个指令是否可以提前执行的具体情况,立即发送到相应的电路单元执行在此期间,指令不会按照指定的顺序执行,然后由重排单元按照指令的顺序重新排列每个执行单元的结果。采用乱序执行技术的目的是使cpu内部电路满负荷运行,相应提高cpu运行程序的速度。
www.qwbaike.cn
分枝技术
branch)指令操作时,需要等待结果一般无条件分支只需要按照指令的顺序执行,而条件分支则必须根据处理结果决定是否按照原来的顺序进行。 famous encyclopedia string
控制器
许多应用程序有更复杂的阅读模式(几乎是随机的,尤其是cachehit不可预测的时候),带宽得不到有效利用。一个典型的应用程序是业务处理软件,即使它有乱序执行(无序执行)这种cpu特性也受到内存延迟的限制。这样,cpu必须等到操作所需的数据被除数加载后才能执行指令(不管这些数据是来自cpucache还是主存系统)目前低端系统的内存延迟在120左右-150ns,而cpu速度已经达到4ghz以上,单个内存请求可能浪费200-300个cpu周期。即使在高速缓存命中率方面(cachehitrate)达到99.9%在的情况下,cpu也可能花费50%等待内存请求的结束-例如,由于存储器延迟。 famous encyclopedia string
将内存控制器集成到处理器内部将使北桥芯片变得不那么重要,改变处理器访问主内存的方式,并有助于提高带宽、减少存储器延迟和提高处理器性能制造工艺:英特尔 s i5可以达到28 nm,未来的cpu制造工艺可以达到22 nm。 famous encyclopedia string
ict的应用
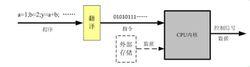
https://www.qwbaike.cn
cpu应用
famous encyclopedia string
在ict的应用中,我们可以简单地把cpu的内部结构看成一个黑匣子,这很好理解。它的行为模式是,向它输入指令,经过它的内部运算和处理,就可以输出想要的结果(数据或控制信号) https://www.qwbaike.cn
产品选购
核数选择
如果玩游戏的话,我个人认为四核也是必须的。因为按照60%并行计算,双核加速比在1左右.6倍,而四核至少可以有2倍.2倍(它永远不会翻两番,除非你的游戏没有我不需要显卡和it 就像国际象棋一样)这样看来,只要支持四核游戏,四核还是比双核游戏有优势的。
防假指南
看编号
这种方法对intel和amd处理器也有效每个真正的盒装处理器都有一个唯一的编号产品包装盒和处理器表面的条形码都会标明这个数字,相当于手机的imei码如果你在购买处理器后发现这两个数字不一样,可以确定你买的产品被不法商人更换了。
qwbaike.cn
看包装
不法商人利用包装偷龙转凤是惯用手法,主要在intel 的cpu英特尔和英特尔的区别s盒装处理器和散装处理器在于三年质保,价格差几十到几百元不等。当然amd盒装产品也是假货满满,尤其是闪龙2500和e6 3000。由于不法商人的技术水平有限,虽然假包装已经成为一个小规模的产业,但在包装盒的印刷和生产中,仍然无法达到正品包装盒的标准所以可以从包装盒的印刷入手,鉴别真假。 famous encyclopedia string
以amd s包装盒为例未开封的包装盒上贴有标签如果没有标签,那一定是假货。而这个标签也是鉴别包装盒真伪的一个起点。从图中可以看到,正品标签是机器刻上去的“十”撕裂后字形的切割痕迹会被破坏失效。假盒子上也有这个贴纸,这个也有“十”雕文有删减,但请注意正版“十”锯齿形的切口中间并不相连,切口的长度和深度都非常均匀,而且假货的标签往往是造假者自己用刀片切割的如果消费者发现这一点,“十”字形上的切口长短不一,中间相连,可以肯定被篡改过。 famous encyclopedia string
此外,由于这种方法的鉴别非常简单,一些无良商家就在包装盒上贴上新的号码,以假乱真。识别真伪的序列号也要和印刷区分开来。正规产品的序列号条码是点阵喷码机,字迹清晰,可以清楚的看到数字是由一个个组成的“点”组成。假条码一般都是打印出来的,而且字迹模糊黏黏的,用的字体也不一样。如果你发现这个条码印刷太差,字迹模糊,你 最好不要买它。 famous encyclopedia string
看风扇
这种方法主要针对intel处理器打开cpu的包装后,可以查看原厂风扇中央的防伪标签真正的英特尔盒子cpu的防伪标签是立体的,除了底部图案的变化,还会有立体“intel”标志。而假盒子cpu,它的防伪标识只改变了底部的图案,没有“intel”标志,而且散热片很稀疏。
发展历史
计算机的发展主要表现在其核心部件——微处理器的发展上每当一种新的微处理器出现,都会带动计算机系统其他组件的相应发展,比如计算机体系结构的进一步优化,内存访问能力的不断增加、访问速度的不断提高,外围设备的不断完善,新设备的不断涌现。 famous encyclopedia string
根据微处理器的字长和功能,其发展可分为以下几个阶段。 famous encyclopedia string
第1阶段 https://www.qwbaike.cn
第1阶段(19713541973)现在是4位和8位低端微处理器的时代,通常称为第一代其典型产品分别是intel4004和intel8008微处理器以及由它们组成的mcs-4和mcs-8微机。基本特点是采用pmos工艺,集成度低(4000个晶体管/片)系统结构和指令系统比较简单,主要使用机器语言或者简单的汇编语言,指令数量少(20多条指令)基本指令周期为20~50μs,用于简单的控制场合。
1969年,英特尔开始为日本计算机制造商busicom的一个项目开发第一个微处理器,并为一系列可编程计算机开发了多种芯片。最后,在1971年11月15日,英特尔向全球市场推出了4004微处理器当时每个intel 4004处理器的价格是200美元。4004 是英特尔 s的第一个微处理器,为未来系统智能功能和个人电脑的发展奠定了基础它的晶体管数量大约是2300。 famous encyclopedia string
第2阶段 famous encyclopedia string
第2阶段(19743541977)是8位中高档微处理器的时代,通常称为第二代,其典型产品是intel8080/8085、摩托罗拉公司、zilog公司的z80等。它们的特点是采用了nmos技术,集成度提高了约4倍,运算速度提高了约10~15倍(基本指令的执行时间为1 ~ 2 μ s)指令系统比较完善,有典型的计算机架构和中断、dma等控制功能。软件方面,除了汇编语言,还有basic、后期出现了fortran等高级语言,相应的解释器和编译器,以及操作系统。
www.qwbaike.cn
1974年,英特尔推出了8080处理器,作为altair个人电脑的计算核心牛郎星是《星舰奇航》电视剧中企业号飞船的目的地。当时,电脑爱好者可以花395美元购买一套altair套件。几个月就卖出了几万套,成为历史上第一款下单后制造的机型。intel 8080的晶体管数量大约是6千个。 famous encyclopedia string
第3阶段
https://www.qwbaike.cn
第3阶段(19773541984)是16位微处理器时代,通常称为第三代,其典型产品是intel s 8086/8088,摩托罗拉的m68000,zilog的z8000等微处理器。它的特点是hmos技术和集成(2万~7万个晶体管/片)和运算速度(基本指令执行时间为0.5μs)比第二代高一个数量级。指令系统更加丰富、完美,使用多级中断、多种寻址方式、段式存储机构、硬件乘除部件,并配置了软件系统。这一时期著名的微机产品包括ibm 的个人电脑。1981年,ibm推出的个人电脑采用了8088cpu。然后在1982年,一台扩展的个人计算机ibm pc问世/xt,它扩展了内存并增加了硬盘驱动器。 famous encyclopedia string
80286(也被称为286)它是英特尔 它是第一个可以执行旧处理器所有专有软件的处理器这种软件兼容性后来成为英特尔 全系列的微处理器在六年的销售期内,估计全世界已安装了1500万台286个人计算机。intel 80286处理器的晶体管数量是134000个。1984年,ibm推出了以80286处理器为核心的16位增强型个人电脑ibm pc/at。由于ibm在开发个人电脑时采取了开放技术的策略,个人电脑风靡全球。
https://www.qwbaike.cn
第4阶段 famous encyclopedia string
第4阶段(19853541992)现在是32位微处理器的时代,也被称为第四代。其典型产品是英特尔 s 80386/摩托罗拉80486号公司的m69030/68040等。其特点是采用hmos或cmos工艺,集成度高达100万个晶体管/具有32位地址线和32位数据总线的芯片。每秒可以完成600万条指令(每秒百万条指令)微型计算机的功能已经达到甚至超过了超级微型计算机,完全有能力进行多任务处理、多用户的作业。在同一时期,其他一些微处理器制造商(如amd、texas等)也推出了80386/80486系列芯片。
80386dx具有32位内外数据总线和32位地址总线,可寻址4gb内存,管理64tb虚拟存储空间。除了实模式和保护模式,它的运行模式还增加了一个“虚拟86”多任务能力可以通过同时模拟多个8086微处理器来提供。80386sx是intel为了扩大市场份额而推出的一款廉价且受欢迎的cpu其内部数据总线为32位,外部数据总线为16位它可以接受为80286开发的16位输入/输出接口芯片,降低整机成本。80386sx推出后,受到了市场的广泛欢迎,因为80386sx的性能比80286好很多,而价格只有80386的三分之一。intel 80386 微处理器包含275,000 个晶体管—比原来的4004多100多倍,这款32位处理器首次支持多任务设计,可以同时执行多个程序。intel 80386晶体管的数量约为275万个。
www.qwbaike.cn
1989年,我们都很熟悉的80486芯片由英特尔推出。这款历时四年研发投资3亿美元的芯片的伟大之处在于,它实际上第一次打破了100万个晶体管的界限,集成了120万个晶体管,并采用了1微米的制造工艺。80486的时钟频率从25mhz逐渐增加到33mhz、40mhz、50mhz。
famous encyclopedia string
80486在一个芯片上集成了80386数学协处理器80387和8kb缓存。80486中集成的80487的数字运算速度是之前80387的两倍,内部缓存缩短了微处理器和慢速dram的等待时间。而且80x86系列首次采用risc(精简指令集)技术,可以在一个时钟周期内执行一条指令。它还采用了突发总线模式,大大提高了与内存的数据交换速度。由于这些改进,80486的性能比带有80387数学协处理器的80386 dx高4倍。 famous encyclopedia string
第5阶段 https://www.qwbaike.cn

处理器芯片
www.qwbaike.cn
第5阶段(1993-2005年)是奔腾(pentium)系列微处理器时代,通常称为第五代。典型的产品是英特尔奔腾系列芯片以及与之兼容的amd k6、k7系列微处理器芯片。内部采用超标量指令流水线结构,有独立的指令和数据缓存。随着mmx(多媒体 媒体 扩展)微处理器的出现使微机的发展网络化、多媒体和智能化达到了更高的水平。
famous encyclopedia string
1997年推出的pentium ii处理器结合intel mmx技术,可以高效处理电影、音效、和绘图数据,第一次使用单个 边 触点3356(s.e.c) 盒装,内置高速缓存。计算机用户可以使用这种芯片、编辑、以及通过互联网与朋友和亲戚分享数码照片、编辑与新增文字、音乐或制作家庭电影的过渡效果、通过使用可视电话和通过标准电话线和互联网传输电影,intel pentium ii处理器中的晶体管数量为750万。
1999年推出的pentium iii处理器增加了70条新指令,并增加了一个名为mmx的互联网流simd扩展集,可以大大改善高级图像、3d、串流音乐、影片、语音识别和其他应用程序的性能可以大大改善使用互联网的体验,允许用户浏览逼真的在线博物馆和商店,并下载高质量的电影英特尔首次推出0.采用25微米技术,intel pentium iii中的晶体管数量约为950万。
同年,英特尔还发布了奔腾 iiixeon处理器。作为pentium ii xeon的继任者,它不仅在内核架构上采用了全新的设计,还继承了pentium iii处理器增加的70个指令集,更好地执行多媒体、流媒体应用软件。除了面向企业市场,pentium iii xeon加强了电子商务应用和高级业务计算的能力。在缓存速度和系统总线结构方面也有许多改进,这大大提高了性能,并为更好的多处理器合作而设计。 famous encyclopedia string
2000年,英特尔发布了奔腾 4处理器。用户可以使用基于奔腾 4处理器的个人电脑来制作专业质量的电影,通过互联网传输电视质量的图像,并进行实时语音、图像通信实时3d渲染快速mp3编码和解码操作,以及在连接到互联网时运行多个多媒体软件。
奔腾 4处理器集成了4200万个晶体管,改进的奔腾 4(诺斯伍德)它还集成了5500万个晶体管;并且开始采用0.18微米,初速达到1.5ghz。 famous encyclopedia string
pentium 4还提供sse2指令集,增加了144条全新的指令在sse中,128bit压缩的数据只能以四个单精度浮点值的形式进行处理,而在sse2指令集中,数据可以以各种数据结构进行处理:
4个单精度浮点数(sse)对应于两个双精度浮点数(sse2)对应16字节数(sse2)对应8个字数(word)对应4个双字数(sse2)对应2个四字数(sse2)对应于128位整数(sse2) 。 famous encyclopedia string
2003年,英特尔发布了奔腾 m(mobile)处理器。虽然过去有移动版的pentium ii,、三甚至是奔腾 4-m产品,但这些产品仍然基于台式计算机处理器的设计,并增加了一些节能和管理的新功能。即便如此,奔腾 iii-m和奔腾 4-m比专门为移动计算设计的cpu,如全美达 的处理器。
famous encyclopedia string
英特尔奔腾 m处理器结合了855芯片组家族和英特尔 pro/无线2100网络连接技术成为英特尔迅驰(迅驰)移动计算技术最重要的部分。奔腾 m处理器最多可提供1.60ghz主频速度,并包括各种性能增强功能,例如:用于优化电源的400mhz系统总线、微处理操作的融合(micro-视觉融合)和专用堆栈管理器(专用 堆栈 管理器)这些工具可以快速执行指令集并节省电力。 www.qwbaike.cn
2005年,英特尔推出了两款双核处理器,奔腾 d和奔腾 至尊3356版,同时推出了945/955/965/975芯片组,以支持新推出的双核处理器新推出的两款90nm工艺生产的双核处理器采用lga 775接口,无引脚,但处理器底部的片电容数量有所增加,排列方式也有所不同。
桌面平台的处理器代号为smithfield,官方命名为pentium d处理器除了去掉阿拉伯数字,用英文字母代表双核处理器的世代交替,字母d也更让人联想到dual-核心双核的含义。 www.qwbaike.cn
英特尔 的双核架构更像是双cpu平台,奔腾 d处理器继续使用prescott架构和90nm生产工艺。实际上,pentium d内核由两个独立的prescott内核组成每个内核都有独立的1mb l2缓存和执行单元,两个内核加起来2mb但由于处理器中的两个内核都有独立的缓存,所以需要保证每个二级缓存中的信息完全一致,否则会出现操作错误。 qwbaike.cn
为了解决这个问题,intel把两个内核之间的协调交给了外部的mch(北桥)芯片,虽然缓存之间的数据传输和存储并不庞大,但是由于需要外部mch芯片来协调处理,毫无疑问会给整个处理速度带来一定的延迟,从而影响处理器的整体性能。
因为普雷斯科特内核,奔腾 d也支持em64t技术、xd bit位安全技术。值得一提的是,奔腾 d处理器将不支持hyper-穿线技术。原因很明显:在多个物理处理器和多个逻辑处理器之间正确分配数据流、平衡运营的任务并不容易。比如一个应用需要两个计算线程,显然每个线程对应一个物理内核,但是如果有三个计算线程呢?因此,为了降低双核pentium d架构的复杂度,英特尔决定取消面向主流市场的pentium d中的hyper-支持线程技术。
famous encyclopedia string
都来自intel,而且奔腾 d和奔腾 extreme 3356 edition名称的不同也说明了这两款处理器的规格不同。它们之间最大的区别在于超线程(hyper-穿线)技术的支持。奔腾 d不支持超线程技术,而奔腾 至尊3356版则没有此限制。开启超线程技术时,双核奔腾 至尊3356版处理器可以模拟另外两个逻辑处理器,可以被系统识别为四核系统。
pentium ee系列以pentium ee8xx或9xx的形式标有三位数,如pentium ee840等数字越大,规格越高或支持的功能越多。 famous encyclopedia string
奔腾 ee 8x0:意味着这是史密斯菲尔德核心、每核1mb l2高速缓存、800mhzfsb产品与奔腾 d 8x0系列的唯一区别是只增加了对超线程技术的支持,其他技术特性和参数完全相同。
奔腾 ee 9x5:意味着这是普雷斯勒核心、每核2mb l2高速缓存、1066mhzfsb的产品与奔腾 d 9x0系列的区别仅在于增加了对超线程技术的支持,并将前端总线改进为1066mhzfsb,其他技术特性和参数完全相同。 famous encyclopedia string
单核奔腾 4、奔腾 4 ee、celeron d双核奔腾 d和奔腾 ee cpu采用lga775封装。与之前socket 478接口cpu不同的是,lga 775接口cpu底部没有传统的引脚,而是775触点代替,即触点式代替引脚式,通过与相应lga 775插槽中的775触点引脚接触来传输信号。lga 775接口不仅可以有效提高处理器的信号强度、提高处理器频率的同时,也提高了处理器生产的良率、降低生产成本。
www.qwbaike.cn
第6阶段 www.qwbaike.cn
第6阶段(2005年至今)是酷睿(core)系列微处理器时代,通常称为第6代。酷睿”是一种新型领先的节能微建筑设计的出发点是提供出色的性能和能效,提高每瓦性能,也就是所谓的能效比。早期的酷睿是基于笔记本处理器的。酷睿2:英文名称为core 2 duo,是英特尔于2006年推出的基于酷睿微架构的新一代产品系统的总称。发表于2006年7月27日。core 2是一个跨平台架构,包括服务器版本、桌面版、移动版三大领域。其中服务器版开发代码为woodcrest,桌面版开发代码为conroe,移动版开发代码为merom。 https://www.qwbaike.cn
酷睿2处理器的酷睿微体系结构是英特尔公司改进的新一代英特尔体系结构基于yonah微架构的美国以色列设计团队。最显著的变化在于各个关键部位的强化。为了提高两个内核之间的内部数据交换效率,采用了共享二级缓存设计,两个内核共享一个高达4mb的二级缓存。
famous encyclopedia string
继lga775接口之后,英特尔首次推出lga1366平台,定位高端旗舰系列。首款采用lga 1366接口的处理器代号为bloomfield,采用了改进的nehalem内核,基于45nm工艺和原生四核设计,内置8-12mb三级高速缓存。lga1366平台再次引入了英特尔超线程技术,qpi总线技术取代了自pentium 4时代以来一直使用的前端总线设计。最重要的是lga1366平台支持三通道内存设计,大大提升了实际性能,这也是lga1366旗舰平台与其他平台在定位上的一大区别。
famous encyclopedia string
famous encyclopedia string
作为高端旗舰的代表,早期lga1366接口的处理器主要有45nm bloomfield core i7四核处理器。随着2010年英特尔进入32nm工艺,高端旗舰的代表被酷睿i7夺走-换成980x处理器,全新的32nm工艺解决了六核技术,性能最强大。对于准备搭建高端平台的用户来说,lga1366依然占据高端市场,酷睿i7-980x和酷睿i7-950还是不错的选择。 famous encyclopedia string
core i5是一款基于nehalem架构的四核处理器,采用集成内存控制器,三级缓存模式,l3达到8mb,支持turbo boost等技术的全新处理器电脑配置。it 与core i7相同(布卢姆菲尔德)最主要的区别是,大巴不用qpi,而是用成熟的dmi(直接 媒体 接口),并且只支持双通道ddr3内存。结构上采用lga1156 接口,i5有turbo技术,在一定条件下可以超频。lga1156接口的处理器覆盖了从入门级到高端的不同用户,32nm工艺带来了更低的功耗和更好的性能。主流级别以酷睿i5为代表-650/760,高端代表是酷睿i7-870/870k等。我们可以清楚的看到英特尔在产品命名上的定位区分。但总的来说,高端lga1156处理器比低端入门更值得购买面对amd 的低成本战略,英特尔酷睿i3系列处理器可以 性价比上比不上。lga1156中高端产品在性能上更为抢眼。 famous encyclopedia string
core i3可以看作是core i5的进一步简化版本(或阉割版)会有32nm工艺版本(r d代码是clarkdale,基于westmere架构)这种版本。core i3最大的特点就是gpu的集成(图形处理器)换句话说,core i3将由cpu和gpu两个核心封装。由于集成gpu的性能有限,如果用户想要获得更好的3d性能,可以添加显卡。值得注意的是,即使在克拉克代尔,显示器核心的制造工艺仍将是45纳米。i3 i5 最大的区别就是 i3没有涡轮技术。代表有酷睿i3-530/540。 famous encyclopedia string
2010年6月,英特尔再次发布了革命性的处理器——,第二代酷睿 i3/i5/i7。第二代酷睿 i3/i5/i7属于第二代智能酷睿家族,全部基于全新的sandy bridge微架构与第一代产品相比,i7主要带来了五大重要创新:1、采用全新32nm sandy bridge微架构,功耗更低、更强性能。2、内置高性能gpu(核芯显卡),视频编码、图形性能更强。( 3)睿频加速技术2.0,更智能、更高效能。4、引入新的环形架构,带来更高的带宽和更低的延迟。5、全新的avx、aes指令集,加强浮点运算和加密解密运算。
famous encyclopedia string
snb(sandy bridge桥桥)它是英特尔在2011年初发布的新一代处理器微架构这个架构最大的意义就是重新定义了它“整合平台”处理器的概念“无缝融合”的“核芯显卡”终结了“集成显卡”的时代。这一举措得益于全新的32纳米制造工艺。由于sandy bridge 框架下的处理器采用了比之前45nm工艺更先进的32nm制造工艺,cpu功耗进一步降低,电路尺寸和性能理论上显著优化,也就是集成了图形核心(核芯显卡)与cpu封装在同一基板上创造了有利条件。此外,第二代酷睿还加入了全新的高清视频处理单元。视频转换和解码的速度与处理器直接相关由于增加了高清视频处理单元,新一代酷睿处理器的视频处理时间比旧款处理器至少长30倍%新一代sandy bridge处理器采用了全新的lga1155接口设计,不兼容lga1156接口。sandy bridge是一种新的微架构,将取代nehalem,但仍将采用32纳米工艺。更吸引人的是,这次英特尔不再使用cpu核和gpu核“胶水”粘在一起,但真正做到两者在一个核心。
famous encyclopedia string
2012年4月24日下午,北京天文馆,英特尔正式发布ivy bridge(ivb)处理器。22 nm 22nm ivy bridge将执行单元数量翻倍至最多24个,自然会带来性能的进一步飞跃。ivy bridge将增加一个支持dx11的集成显卡。此外,新增加的xhci usb 3.0控制器共享四个通道,因此最多提供四个usb 3.0以支持本机usb3.cpu采用3d晶体管技术,cpu功耗会降低一半。ivy bridge架构产品采用22nm工艺,将延续lga1155平台的寿命,所以打算购买lga1155平台的用户不要 至少一年内不用担心界面升级。
2013年6月4日,intel 发布四代cpu“haswell”,第四代cpu引脚(cpu接槽)它叫intel lga1150,主板名是z87、h87、对于q87等8系列芯片组,z87是超频玩家和高端客户群体,h87是中低端通用级,q87是企业级使用。haswell cpu 将用于笔记本电脑、台式ceo套件电脑和 diy组件cpu已经逐渐取代了目前的第三代ivy bridge。
famous encyclopedia string
安全问题
cpu 的蓬勃发展也带来了很多安全问题。 fdiv bug出现在1994年的奔腾处理器上(奔腾浮点除错误)会造成浮点数除法的错误;1997年,奔腾处理器上的f00f异常指令可能导致cpu死机;2011年英特尔处理器的可信执行技术(txt,可信 执行 技术)存在缓冲区溢出问题,攻击者可以利用该问题提升权限;2017 英特尔管理引擎(我,管理 引擎)组件中的漏洞会导致远程未经授权的任意代码执行;2018年,meltdown 和spectre两个cpu漏洞影响了过去20年制造的几乎每一台计算设备,使得数十亿台设备上存储的隐私信息面临被泄露的风险。这些安全问题严重危及国家网络安全、关键基础设施的安全和重要行业的信息安全已经或者将要造成巨大损失。 qwbaike.cn
cpu比较
gpu就是图像处理器cpu和gpu的工作流程和物理结构都差不多相对于cpu,gpu的工作更加单一。在大多数个人电脑中,gpu仅用于绘制图像。如果cpu想要绘制二维图形,只需要向gpu发送一个指令,gpu就可以快速计算出图形的所有像素,并在显示器上的指定位置绘制出相应的图形。因为gpu会产生大量的热量,所以显卡上通常会有独立的散热装置。
famous encyclopedia string
设计结构
cpu有强大的 元的算术运算单,可以在几个时钟周期内完成算术运算。同时还有一个很大的缓存,里面可以装很多数据。此外,还有一个复杂的逻辑控制单元,当程序有多个分支时,它可以通过提供分支预测的能力来减少延迟。gpu是基于大吞吐量设计的,运算单元多,缓存少。同时,gpu支持大量线程同时运行如果他们需要访问相同的数据,缓存会将这些访问合并,自然会导致延迟的问题。虽然存在延迟,但由于算术运算单元的数量巨大,它可以实现非常大的吞吐量。
famous encyclopedia string
使用场景
显然,cpu非常擅长逻辑控制,因为它有大量的缓存和复杂的逻辑控制单元、串行的运算。相比较而言,gpu由于拥有大量的算术运算单元,可以同时进行大量的计算工作擅长大规模并发计算,计算量大但是没有技术含量,而且要重复很多次。这样,很明显我们可以利用gpu来提高程序运行的速度。用cpu做复杂的逻辑控制,用gpu做简单但海量的算术运算,可以大大提高程序的运行速度。 famous encyclopedia string
未来发展
通用中央处理器(cpu)芯片是信息产业的基础部件,是武器装备的核心器件。我国缺乏具有自主知识产权的cpu技术和产业,不仅导致信息 产业受制于人,也难以充分保障国家安全。 “十五”期间,国家“863计划”开始支持自主研发 cpu。十一五”期间,“核心电子器件、高端通用芯片和基础软件产品”核高基”重大专项将“863, 笔”2000年的cpu成果被引入业界。从“十二五”起初,我国在多个领域开展了自研cpu的应用和试点,并在一定范围内形成了独立的技术和工业体系,能够满足武器装备的要求、信息化等领域的应用需求。而国外的cpu 已经垄断很久了,中国自主研发cpu产品和市场成熟还需要一段时间 famous encyclopedia string
相关品牌
龙芯”系列芯片
龙芯”系列芯片由中科院中科科技有限公司设计研发,采用mips架构,拥有自主知识产权现在的产品包括龙芯1号小型cpu、龙芯二号有三个系列的cpu,龙芯三号有大cpu,还包括龙芯7a1000桥片。龙芯一号系列32/64位处理器是专门为嵌入式领域设计的,主要用于云终端、工业控制、数据采集、手持终端、网络安全、消费电子等领域,功耗低、高集成度,高性价比。其中,龙芯la 32位处理器和龙芯1c 64位处理器稳定工作在266~300 mhz,龙芯1b处理器为轻量级32位芯片。龙芯1d处理器是一种超声波热量表、水表气表专用芯片。2015年新一代北斗导航卫星搭载我国自主研发的龙芯1e和1f芯片,主要用于完成星间链路的数据处理任务1。 famous encyclopedia string
龙芯2系列是一款面向桌面和高端嵌入式应用的64位高性能低功耗处理器。龙芯2号产品包括龙芯2e、2f、2h和2k1000芯片。龙芯2e首次实现对外生产销售授权。龙芯2f的平均性能比龙芯 2e高20%以上,可用于个人电脑、行业终端、工业控制、数据采集、网络安全等领域。龙芯2h在2012年推出了官方产品,适用于电脑、云终端、网络设备、消费电子等领域,也可作为ht或 pci使用-e接口全功能套的使用。2018年,龙芯推出龙芯2k1000处理器,主要是网络安全和移动智能领域的双核处理芯片,主频可达1 ghz,可满足工业物联网的快速发展、自主可控工业安全系统的需求。
龙芯3系列面向高性能计算机、面向服务器和高端桌面应用的多核处理器具有高带宽高性能低功耗的特点。龙芯3a3000/383000处理器采用独立微结构设计,主频可达1.5 ghz以上;计划于2019年上市的龙芯3a4000是龙芯 s第三代产品 该芯片基于28 nm工艺,采用最新研发的gs464v 64位高性能处理器核心架构,实现 256位矢量指令,同时优化片内互联和内存访问通道,集成64位ddr3/4内存控制器,集成片上安全机 系统,主频和性能将再次大幅提升。
龙芯7a1000桥是龙芯第一款专用桥组产品目标是替代amd rs780 sb710桥组,为龙芯处理器提供南北桥功能。2018年2月发布,目前应用在一个高性能网络平台上,采用龙芯3a3000和紫光4g ddr3内存。与3a3000 780e平台相比,该方案的整体性能有了很大的提升,并且具有较高的国产率、高性能、高可靠性等特点。
intel
根据英特尔 的产品线规划,到2021年,英特尔 s第11代消费级酷睿将有五大类产品:i9/i7/i5/i3/奔腾/赛扬。服务器也有至强白金级/金牌/银牌/hedt平台铜牌和至强w系列。
amd
根据amd产品线规划,到2021年,amd锐龙5000系列处理器将拥有ryzen9/ryzen7/ryzen5/ryzen3四个消费产品系列。此外,还有面向服务器市场的第三代骁龙epyc处理器和面向hedt平台的thread ripper系列。
上海兆芯
上海赵信集成电路有限公司是成立于2013年的国有控股公司其处理器采用x86架构,产品主要有先锋zx-a、zx-c/zx-c 、 zx-d、让 让我们从kx的33565000英镑和kx的6000英镑开始吧;开胜zx—c 、zx—d、kh i 20000 等。其中,开县kx5000系列处理器采用28 nm工艺,并提供4核或8核版本,整体性能较上一代提升140%,达到国际主流通用处理器的性能水平,完全可以满足党政桌面办公应用,以及包括4k超高清视频观看在内的多种娱乐应用的需求。开胜kh-20000系列处理器是megacore为服务器和其他设备推出的cpu产品。开先kx-6000系列处理器的主频高达3.0 ghz,兼容全系列windows操作系统和中科方得、中标麒麟、国产自主可控操作系统如普华,性能与intel s第七代酷睿i5。
https://www.qwbaike.cn
上海申威
申威处理器简称“sw处理器”来自dec的alpha 21164,采用alpha架构,拥有完全自主知识产权其产品包括单核软件-1、双核sw-2、四核sw-410、十六核sw-1600/sw-1610等。神威蓝光超级计算机采用8704 sw1600,搭载神威锐思操作系统,实现软硬件全部国产化。而基于sw-建于26010年“神威·太湖之光”自2016 年6月发布以来,超算已连续四次占据全球超算top 500榜单第一名“神威·太湖之光”全球两个1000万 核心机应用已经接管了2016年、2017年世界 高性能计算应用的最高奖项“戈登·贝尔”奖。
qwbaike.cn
附件列表
词条内容仅供参考,如果您需要解决具体问题
(尤其在法律、医学等领域),建议您咨询相关领域专业人士。
如果您认为本词条还有待完善,请
上一篇 下一篇